Кейс про нашу собственную систему
Этот кейс — про наш собственный проект: xaverPRO и xaver.ru, двуязычное портфолио из 107 кейсов на каждом языке. Мы собрали его себе тем же конвейером и с той же дисциплиной, что и клиентские сайты.
История не про хронологию и не про «как прошли эти месяцы». Она про систему. Сложную задачу — собрать сотню проектов из трекера, нормализовать, перевести, проверить и опубликовать на двух языках — мы разложили на звенья, выстроили из них конвейер и каждое звено довели до рабочего состояния.
В этом и есть наша работа: взять сложную задачу, разобрать её на части, собрать под неё конвейер и отвечать за результат на выходе. Свой сайт — просто задача, которую мы поставили себе сами. Дальше — разбор системы по звеньям.
Краткий обзор
| Поле | Значение |
|---|---|
| Тип проекта | Внутренний проект — двуязычный сайт-портфолио бюро |
| Формат сотрудничества | Для собственного использования |
| Целевой покупатель | xaverPRO: SEO/маркетинговые агентства США/Великобритании/ОАЭ · xaver.ru: русскоязычные студии и CTO в РФ, СНГ, ОАЭ и на Кипре |
| Объём работ | 107 опубликованных кейсов · 22 страницы · 5 эссе · 7 отраслевых страниц · 5 опорных страниц — на каждом из двух языков |
| Дата проекта | 09.02.2026 – 22.05.2026 (103 дня) |
| Активная разработка | ~35 дней (между фундаментом и основной работой 2 месяца паузы) |
| Трудозатраты | ~400 часов |
| Команда | 4: Антон Херсун + Claude Opus 4.7 (оркестратор) + Claude Sonnet 4.6 (субагенты) + DeepSeek v4 Pro/Flash через OpenCode |
| Технологический стек | WordPress 6.9 · Astra free 4.13 + дочерняя тема xaver-pro · PHP 8.4-fpm-alpine · MariaDB 11.4 · Redis · nginx · Rank Math · конвейер деплоя на shell-скриптах · Python-инструментарий обработки кейсов |
| Сдано | Два рабочих сайта (xaverPRO EN + xaver.ru RU), 107 опубликованных кейсов на каждом, единая тема на серверном PHP-рендере, схема деплоя, обновляющая только контент, ~30 Python-скриптов и ~12 Claude-навыков |
| Коммитов | 823 в ветке feature/ai-importer |
| Версий темы | v0.1.0 → v1.0.458 (458 синхронных шагов) |
Конвейер в одну схему
Любую сложную задачу мы начинаем одинаково: раскладываем на звенья и смотрим, как данные текут от одного к другому. Вот эта задача в одной схеме — пять звеньев, данные идут в одну сторону, от трекера задач к двум готовым сайтам. Каждое звено делает свою работу и передаёт следующему.
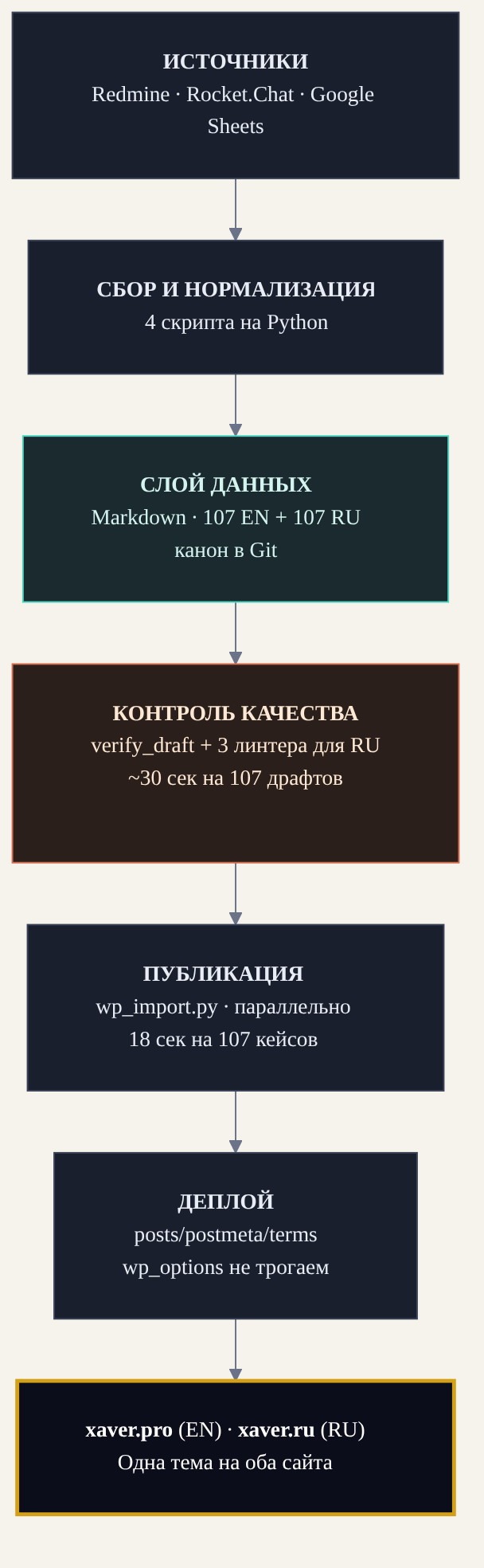
- Источник правды — Redmine. История задач, часов и статусов 112 проектов уходит в JSON. Дальше — детерминированный разбор: тип работы, согласованные часы, состав команды.
build_matrix.pyразложил все 112 проектов по приоритету за 47 секунд: 52 в первую очередь, 54 во вторую, 6 в отказ. - Извлечение контекста — Rocket.Chat. Из тысяч, а то и десятков тысяч сообщений по проекту фильтр оставляет десяток по делу. Здесь же мы наступили на первые грабли: набор регулярных выражений понимал только английский и выдавал 25 сигналов там, где их было за сотню. Почти вся переписка шла на русском. Двуязычный словарь поднял охват до 100+ на проект.
- Нормализация и генерация — LLM. DeepSeek v4 и Claude-субагенты собирают markdown-черновик по жёсткому шаблону под тип работы: Rebuild, Build, Templated, Refresh, Redesign, Other. Шаблон — это не творческое задание, а контракт: какие секции, в каком порядке, с какими обязательными полями.
- Контроль качества — Python.
verify_draft.py, 48 проверок: есть ли согласованные часы, жив ли URL, не сполз ли текст в шаблон, не утекли ли учётные данные. Скрипт чистки секретов нашёл и вырезал 19 фрагментов уже в первом кейсе: пароли из чатов, ссылки на тестовые среды, личные аккаунты. Поверх — четыре линтера русского текста. - Доставка — пакетный деплой контента. Атомарная транзакция, три прохода перезаписи URL, восьмиступенчатая проверка, изоляция первичных ключей. Один скрипт, один источник конфигурации на оба сайта.
Это вся система. Дальше — каждое звено по отдельности: где оно упёрлось в свой предел и как мы довели его до рабочего состояния. Начнём с последнего, доставки: именно оно решает, попадёт ли работа на боевой сайт целой.
Звено доставки: деплой, который не трогает боевой сайт
Самое тревожное в передаче деплоя подрядчику — что очередное обновление контента затрёт то, что живёт только на боевом сайте: активные плагины, настройки SEO, флаги индексации. Один такой деплой — и после каждой синхронизации кто-то руками поднимает конфигурацию обратно. Для агентства это не теория, а простой вопрос: пускать ли вообще подрядчика к боевому сайту клиента.
Спецификация у этого звена жёсткая: трогать только посты, метаданные, термины и таксономии — и больше ничего. Таблица wp_options с настройками Rank Math и списком плагинов остаётся нетронутой. Логика простая: контент и конфигурация живут в разных ритмах. Контент меняется каждый день, конфигурация — редко и осознанно. Смешать их в одном деплое значит каждый раз рисковать конфигурацией ради контента.
Первый подход к этому не дотягивал. Точечный SQL-дамп под нужные типы постов сработал бы для одного деплоя, но следующий снова потребовал бы разбора данных и нового дампа под них. Точечные файлы выбросили, написали единый скрипт с предсказуемой логикой — и сразу увидели риск конфликта первичных ключей.
Вот в чём он. На боевом сайте в таблице постов живут не только наши записи: тот же Flamingo, хранилище заявок Contact Form 7, складывает свои в ту же таблицу, что и редакционный контент. Деплой, который перезаписывает посты по их номерам, рано или поздно встретит чужую запись на «своём» номере. Лечить такое постфактум — плохая стратегия для того, что ходит на боевой сайт.
Поэтому конфликт мы убрали по построению, а не понадеялись на низкую вероятность. Редакционный контент занял номера 1–999 999. Данные боевого сайта (Flamingo и прочие плагины, что копят свои записи в работе) уехали в диапазон от 1 000 000, а автоинкремент таблицы постов прибили к 1 001 000. Пересечься этим диапазонам больше негде. Конфликт стал не «маловероятным», а невозможным.
Финальный прогон прошёл чисто: 1,7 МБ атомарного SQL, 107 кейсов, 7 канонических таксономий за один проход. Два контрольных повтора той же ночью уложились в 2 минуты каждый, оба зелёные, второй уже слал в Telegram отчёт по каждой стадии.
Та же схема тянет оба языка. Все различия между сайтами (путь на VPS, системный пользователь, префикс таблиц, URL, FPM-пул) собраны в одном файле _targets.sh с переключателем TARGET=en|ru. Скрипты деплоя подключают его как зависимость. Добавить третий сайт — одна строка, а не правки в пяти местах.
Проблема масштабирования: 17 минут → 18 секунд
17 минут на полный реимпорт 107 кейсов. 20 вызовов docker exec на каждый: тело поста, метаданные, главная картинка, мобильная, таксономии. Мы терпели это 2 недели. Зря. На 20 постах ещё терпимо, на 107 — стоп-машина: правишь 1 кейс, ждёшь 3 минуты ради него 1.
Рефакторинг свёл двадцать вызовов к одному. wp eval-file выполняет PHP-скрипт прямо в контексте WordPress: все правки кейса в одном скрипте, переданном через смонтированную папку, без копирований внутрь контейнера. Плюс пул потоков по числу задач. 17 минут стали 18 секундами. В 54 раза.
Число 54 у нас стало нарицательным, и не потому, что красивое. Дело не в самих 17 минутах: один-два реимпорта в день они спокойно выдерживали. 18 секунд изменили не скорость задачи, а саму форму работы: реимпорт стал бесплатным, регрессию видно в момент её появления, итерация перестала стоить времени.
Здесь весь принцип, по которому росла эта машина: инструмент рождается из боли, а не из плана. Первый кейс мы прошли руками, шаг за шагом. Иначе все автоматизации встали бы на непроверенной методике. Потом ту же методику прогнали через 5 проектов параллельными агентами. Потом появился build_matrix.py, разложивший 112 проектов за один прогон. Потом verify_draft.py с 48 проверками, потому что агенты ошибались в предсказуемых местах. Каждый инструмент — ответ на узкое место, которое вскрыл предыдущий шаг.
Текст как код: четыре линтера и трёхэтапный аудит
Качество текста у нас — инженерная задача с тестами, а не вопрос вкуса. 214 кейсов на двух языках глазами после каждого прогона автоматизации не вычитать. Поэтому проверки оформлены как код.
Один пример, с которого всё началось. На первом прогоне линтер поймал 398 кальк. Каталог запрещённых форм с тех пор дорос до 8 000 строк правил.
# .claude/skills/ru-translation-quality/anti_patterns.json
"aggregate_matched_calque": {
"rule_class": "calques_forbidden",
"severity": "error",
"patterns": [
"агрегат сошёлся",
"сумма сошлась в согласованные",
"итог сошёлся в N часов"
],
"suggested": "→ «итоговый объём уложился в согласованные N часов»",
"source": "EN-калька с «the aggregate came in at the agreed N hours»"
}
До правила и после:
Агрегат сошёлся в согласованные 78 часов проекта.
Итоговый объём уложился в согласованные 78 часов проекта.
Грамматика чистая в обоих. Но первый вариант по-русски не звучит: неодушевлённое существительное действует в нём по английской модели. Регулярное выражение этого не видит. Каталог из 8 000 правил — видит.
Линтеров четыре, и каждый закрывает свой пласт:
- Лексический — англицизмы и кальки-слова. По каталогу из 8 000 правил. Ловит «продакшен», транслитерации вроде «абонементной поддержки» и сотни им подобных.
- Грамматический — на Natasha и pymorphy3. Ловит рассогласование прилагательного с существительным по роду и подлежащего с глаголом прошедшего времени. Это побочка массовых замен: меняешь существительное на форму другого рода, а согласованные с ним слова остаются от старой. Руками это ловится только чтением, линтером — за секунду на весь корпус.
- Кросс-языковой — сверяет бренды и имена. Между EN- и RU-версией кейса, через фонетику плюс расстояние Левенштейна. «Vista Family Eyecare» должно остаться латиницей, а не стать «Виста Фэмили Айкэр». Заодно линтер вскрыл артефакт извлечения: в 2 кейсах среди нашей команды оказался человек, которого в ней не было, — сотрудник агентства-заказчика, общавшийся с нами в общем чате. Алгоритм принял его за своего. Убрали.
- Индекс имён команды. Канонический EN- и RU-вариант на каждого из 11 человек, без смешения латиницы и кириллицы.
Но главное мы поняли позже: чистый линтер не означает чистый текст. Линтер закрывает уровень слов. На уровне фразы остаются кальки, которые регулярка не возьмёт в принципе: неодушевлённый субъект по английской модели («the aggregate came in» → «сумма сошлась»), английская метафора без русского эквивалента («client build has a visible victim»), глагол со словарным переводом, но чужим употреблением («timeline accommodates 170 hours», где календарный срок «вмещает» часы). Грамматика чистая, линтер молчит — а носитель спотыкается уже на чтении вслух.
Отсюда трёхэтапный аудит, который стал стандартом:
- Этап 1 — дешёвая быстрая модель. DeepSeek Flash, ~6 минут на кейс, доли цента. Механические артефакты, согласование, простые англицизмы: всё, что проскочило мимо первого линтера.
- Этап 2 — Claude Sonnet. Дороже и медленнее, зато видит структурные кальки: перевод, верный по словам и калькированный по конструкции, падежи в именах собственных, смешение регистров, причастную кашу.
- Этап 3 — ручное чтение от начала кейса до конца. На одной партии этот проход поймал 22 ошибки, которые модель не увидела или поправила по-своему неверно. Правило закрепили: третий этап — это чтение целиком, а не просмотр правок второго.
И ещё одна дисциплина: «критик сказал — значит надо» не работает. Часть замечаний — ложные срабатывания. «Таксономия услуг» — устоявшийся русский IT-термин, технический директор его знает. «QA-тестирование» — тавтология: QA и есть тестирование, и принять такую правку было бы ошибкой. Каждое замечание мы сверяем с правилами проекта. Автоматически не принимается ничьё мнение: ни критика, ни линтера. Последнее слово — за человеком. Инструменты подсказывают, но не решают.
i18n: контент в коде, не в базе
План русской версии был наивным: открыть страницы в админке, перевести, сохранить. Через час выяснилось, что план не работает. Страницы xaverPRO не хранят контент в базе вообще — в теле поста ноль слов. Весь текст рендерится из PHP-шаблонов темы, и каждая строка обёрнута в gettext (__(), _e()).
По-инженерному это правильно. Контент в коде версионируется в Git вместе с темой, не уплывает в базу, не теряется при миграциях. И отсюда главное следствие: деплой кода и деплой контента разъехались. Перевод — это не правка записей в WordPress, а работа с файлом .po: строки собираются в шаблон, переводчик переводит, компилятор делает бинарный .mo, WordPress на лету подменяет язык. В каталоге ru_RU.po собрано 1719 строк.
Цена решения: «просто перевести в админке» уже нельзя. Зато 2 сайта живут на одной кодовой базе, и обновление темы едет на оба одним деплоем кода, отдельным от деплоя контента. Выгода эту цену перевешивает.
Управление техдолгом: где мы остановились
Лучшее — не всегда максимальное. Зрелость команды видна не в том, что она выжимает каждую метрику до максимума, а в том, что она знает, где остановиться, и фиксирует границу — чтобы следующий разработчик не бился в ту же стену.
Мобильный PageSpeed 100, которого нет. На больших экранах сайт держал 100. Мобильный замер на 99, и один балл выглядел как последняя миля. Техника известная: выделить критический CSS, встроить в HTML, остальное грузить асинхронно. Перед боем мы построили страховку, стенд визуальной регрессии: съёмка через Playwright на 28 URL в 5 контрольных точках, сравнение пар снимков тремя алгоритмами (перцепционный и дифференциальный хэш, индекс структурного сходства), разбивка на плитки. Калибровка дала 0 расхождений из 140 пар. Инструмент извлечения вынул 28 КБ критического CSS из 262 — разумная доля.
Деплой тут же вскрыл несовместимость, которой раньше никто не замечал. Шапка грузит шрифт по стратегии font-display: optional, а окно его загрузки держится на блокирующем отрисовку CSS. Встраиваешь критический CSS — и парсинг становится мгновенным: окно схлопывается, браузер берёт запасной шрифт, заголовок переносится на 2 строки, а стабильность компоновки прыгает с 0,021 до 0,174. Повторили на 2 прогонах в тёплом кэше. Закономерность, не случайность.
Быстрая мобильная отрисовка и нулевой сдвиг вёрстки оказались взаимоисключающими при текущей шрифтовой архитектуре. Порядком загрузки это не лечится — нужна перестройка шрифтов целиком, отдельная задача с риском сломать остальное. Решение: оставить мобильный 99 со стабильностью в зелёной зоне. Это устойчивый оптимум, а не компромисс. Границу мы измерили, записали в дизайн-кит, POC сохранили в архиве. Ломать боевой сайт ради цифры 100 в чужом отчёте мы не стали.
Настоящие 100/100/100/100 на больших экранах пришли с другой стороны: мы убрали из очереди 2 неиспользуемых JavaScript-файла родительской темы Astra, и блокировка отрисовки упала с ~70 мс до нуля. Цифру не подгоняли — выкинули лишнее.
Консолидация — тоже дизайн, и часто более глубокий, чем новые элементы. За месяц overrides.css распух почти до 9 000 строк, и около 40% дублировалось между пространствами имён под 5 типов кейсов. Симптомы видно глазом: «бровь» над заголовком 10 пикселей на одной странице услуг и 11 на другой, 2 страницы без переменной фона, длинное тире, нарисованное дважды символом в тексте и CSS-псевдоэлементом. Заменили на универсальные компоненты .xpro-*: 1 .xpro-hero вместо 5, 1 .xpro-cta-band на все CTA, постраничный модификатор перекрывает только акцент. 8 фаз закрыли за одну сессию: половинчатая консолидация даёт половинчатый эффект, и обходные решения возвращаются. Видимая часть результата — минус 242 строки; реальная сложность упала сильнее. 7 отраслевых хабов теперь работают на одном шаблоне вместо 7 почти одинаковых копий.
Масштабируемость — это не когда у вас много страниц. Это когда новую можно добавить, не трогая старые.
Граница: мы не делаем SEO
Скажем прямо: SEO-продвижение мы не продаём. Но фундамент разработки строго ложится под требования современных поисковых алгоритмов — иначе сайт на 200 страниц просто не виден. Это часть инженерной работы, а не отдельная услуга, и границу эту мы держим открыто.
Как мы относимся к SEO-советам, лучше всего показывает один эпизод — и он неприятный. Первую версию плана оптимизации мы прогнали через четыре независимые проверки с выборкой из актуальной литературы. Четыре тактики, каждая поданная как «прогрессивная практика», на проверке оказались способом активно угробить выдачу:
- тип
CaseStudyв разметке Schema.org: такого типа не существует, разметка невидима для сниппетов; - тасовка 5–6 структурных блоков ради «уникальности»: ровно тот маркер, по которому Google помечает контент как машинный;
- накрутка даты модификации без реальных правок: «дата-стаффинг», за который с 2023 года прилетает ручной фильтр;
- автоперелинковка по совпадению сущностей 3 и более раз: топология ссылочной фермы.
План v1 отвергли целиком. v2 оставил только то, что работает на алгоритмах 2024–2025: разметку Person и Organization, согласованность сигналов между страницами, осмысленный якорный текст вместо «click here», Article на кейсах, «отпечатки опыта» (концепция E-E-A-T) — абзац с реальной проблемой и предложение с обоснованием решения в каждом кейсе.
Вывод тут не про SEO, а про метод. Любой совет из открытых источников проходит у нас один фильтр — работает ли это сегодня или за это прилетает санкция? SEO меняется быстрее, чем устаревают руководства «как сделать SEO». Тот же фильтр мы держим на любой внешний совет, не только на поисковый.
Что мы построили и не стали использовать
Честный кейс показывает не только победы. Первые 6 дней мы поднимали MCP-федерацию из 219 инструментов — три сервера под одной точкой доступа с токеном (71 + 3 + 145). Работа чистая: ресурсные лимиты Docker, переиспользование соединений через keep-alive после того, как системный сторож памяти в первый же вечер начал убивать процессы, замена тяжёлой темы на лёгкую Astra ради экономии памяти.
А потом она не пригодилась. Когда в апреле пошла настоящая работа, все операции с админкой поехали через mcp-ssh — он оказался кратно быстрее. Федерация так и осталась стоять: рабочая, нетронутая, в стороне от критического пути. Вывод мы записали честно: хорошая инфраструктура не требует, чтобы её использовали. Иногда правильно построенный узел оказывается не той осью, вокруг которой пойдёт работа. И это нормальный исход, а не списанные впустую часы. Важно вовремя это увидеть и не тащить мёртвый канал в основную схему только потому, что он уже построен.
Принципы, которые остались
Это правила не про наш сайт, а про то, как мы берёмся за любую систему — на вашей задаче они работают так же.
- Инструмент строится по боли, а не по плану. Сначала руками, потом автоматизация, потом доработка под проблему, которую вскрыла сама автоматизация.
- Чистый линтер не означает чистый текст. Машина ловит слова, человек — структуру. Три прохода аудита, а не два.
- Контент и конфигурация живут в разных слоях. Деплой, который их смешивает, рано или поздно затрёт настройки боевого сайта.
- Границу честнее измерить, чем обойти. Мобильный 99 с зелёным CLS лучше, чем 100 ценой прыгающей вёрстки — и про это есть запись в дизайн-ките.
- Решение остаётся за человеком. Ни критик, ни линтер, ни модель не принимаются на веру.
Если у вас аналогичная задача
Вы видели, как мы разобрали свою задачу. Если у вас есть своя — сложный сайт, конвейер контента, система из нескольких звеньев, которую надо собрать и довести до результата, — пришлите текущий стек: какая CMS, какие источники данных, как организован деплой. Посмотрим, выделим узкие места, вернём фиксированную оценку в часах. Аудит бесплатный.
Пока нет ТЗ? Пришлите описание в один абзац — вернёмся с вопросами, которые стоит задать. Прислать описание →
Числовое приложение
Объём работы
- Календарь: 09.02.2026 → 22.05.2026 = 103 дня (из них ~35 дней активной работы; 2 месяца паузы между фундаментом и основной работой)
- Коммитов: 823 в
feature/ai-importer - Веток: 5 (основная плюс четыре тематические: миграция темы, генерация кейсов, AI-импортёр, федерация шлюза)
- Плановых документов закрыто: 106 в
plan/done/ - Документации в
docs/: ~25 файлов (дизайн-кит, инструкция по деплою, маркетинговые материалы)
Контент
- Опубликованных кейсов: 107 RU + 107 EN = 214 case_study на обоих сайтах
- Статических страниц: 22 RU + 22 EN = 44
- Эссе-инсайтов: 5 RU + 5 EN = 10
- Страниц по отраслям: 7 RU + 7 EN = 14
- Опорных страниц (типы кейсов): 5 RU + 5 EN = 10
- Покрытие 112 Redmine-проектов: 100% (52 высокого приоритета + 54 публикуемых + 6 на пропуск; проект №23 разделён на 23.1 и 23.2)
- Каталог i18n темы: 1719 строк в
ru_RU.po
Инструментарий
cases/scripts/: 30+ Python-скриптов (build_matrix, verify, wp_import, translate, audit, sync, redact, fetch_sheet и др.)scripts/deploy/: 8+ shell-скриптов (full_deploy.sh,content_deploy*.sh,_targets.sh, verify, profile и др.)- Тема
xaver-pro/: ~60 PHP-файлов, серверный рендер, 11 шаблонов страниц + 5 шаблонов одиночных кейсов + универсальные компоненты.xpro-* - Линтеры русского текста: лексический (
anglicism_lint.py), грамматический (agreement_lint.py, Natasha + pymorphy3), кросс-языковой (cross_language_ner_check.py)
Деплой и масштаб
- Реимпорт корпуса: 17 минут → 18 секунд (ускорение в 54 раза)
- Диапазоны первичных ключей: редакционный контент 1–999 999, данные боевого сайта от 1 000 000
- PageSpeed на запуске xaverPRO: 66 → 99/99/100/100 (WebP-конвертация 2 235 файлов, −86,6% веса изображений)
- OpenCode на DeepSeek: ~190 атомарных единиц за 5+ раундов, суммарная стоимость ~$2–4